How to fix technical SEO issues on client-side React apps

Google’s web crawlers have come a long way in recent years in their ability to fetch and execute JavaScript.
However, JavaScript integration remains tricky when setting up the front end of a web app.
It requires extra network calls and processing time to load content, which increases browser CPU usage and page load times.
A web app that relies entirely on client-side JavaScript can still exceed the capacity of Google’s Web Rendering Service (WRS), making it difficult for Googlebot to crawl and index content.
JavaScript is still the backbone of the web – the only language that can run natively in the browser.
At the same time, the rise of large language models (LLMs) has triggered a surge in web crawlers searching for quality content to train their datasets.
However, recent studies show that many of these crawlers can’t execute JavaScript – they can only fetch it.
That’s why it’s crucial to know how to diagnose common JavaScript-related issues and address potential crawling or indexing delays before they affect your technical SEO.
The role of JavaScript libraries in the indexing flow
Websites have been heavily reliant on JavaScript for quite some time.
With the rise of large language models, more is being built, and faster.
But speed can blur the details, so it’s important to stay vigilant about how JavaScript impacts your site’s crawlability and indexing.
JavaScript libraries are collections of pre-written code that developers can plug into their projects to handle specific tasks, like:
- DOM manipulation.
- HTTP requests.
- Metadata injection (the latter being a potential SEO red flag).
Crucially, these libraries operate under the developer’s control.
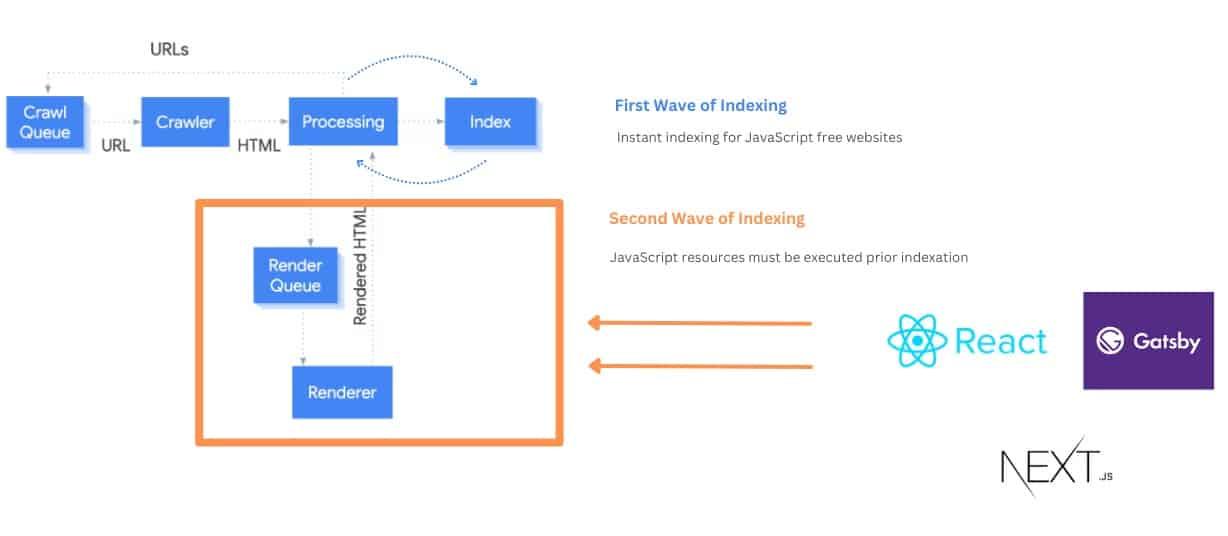
Take React, for example, a popular JavaScript library that allows developers to build reusable components in JavaScript and assemble them on a page.
However, because this new content doesn’t exist in the original HTML, it’s typically discovered during what’s known as the second wave of indexing, when search engines revisit the page to render and process JavaScript content.

Notice that JavaScript is resource-intensive (Googlebot crawls over 130 trillion pages).
It can eat into your crawl budget, especially for large ecommerce sites with many JavaScript-powered pages.
This can inevitably deter your crawl budget allocations and prevent correct rendering.
Dig deeper: SEO for reactive JavaScript using React or Vue with NodeJS and other backend stacks
React rendering: Client-side vs. server-side
A React application can be rendered either on the server or in the browser (client-side).
Server-side routed web applications render JavaScript on the server for each request, forcing a full page reload each time a page load is submitted.
Despite being resource-intensive and slightly subpar from a UX standpoint, it reinforces consistency between the Googlebot-rendered view and that of the average user in the front end.

The most common and default approach for modern web apps is client-side rendering.
In this setup, the server delivers an empty page that will be filled as soon as the browser finishes downloading, parsing, and running the JavaScript.
While not as common in ecommerce, some platforms, such as Adobe PWA Studio, are still fully client-side rendered.

This configuration can be problematic for SEO, and it’s intrinsically tied to the setup of the so-called React Router, a popular solution for managing routes in single-page applications (SPAs).
For those with limited technical knowledge, “routing” in web apps enables smooth transitions between pages without needing a full page reload from the server.
This results in faster performance and reduced server bandwidth load when navigating between pages.
Think of the router in a React app as the traffic controller at the very top of your component hierarchy. It wraps your whole application and watches the browser’s address bar.
As soon as the URL changes, the router decides which “room” (component) to show, without ever reloading the page, unlike a traditional website, which requests a page from the server upon each navigation.

In React apps, routers use dynamic paths, like /product/:id, to load page templates without a full refresh.
The : means the value changes based on the product or content shown.
<Routes>
<Route path="/" element={<Home />} />
<Route path="/note/:noteId" element={<NoteDetailPage />} />
</Routes>While this is great for user experience, poor configuration can backfire on SEO, especially if this is performed client-side.
For example, if the router generates endless variations of URLs (like /filter/:color) without returning a full server response, search engines might have a tough time rendering and indexing them.
How a faulty router can hurt indexing
During a recent SEO audit for a notorious car manufacturer, we discovered a routing issue that severely impacted indexing.
A dynamic filter on a category listing page used a placeholder route segment (e.g., /:/). This resulted in URLs like /page-category/:/ being accessible to search engines.
This is usually on the router and how it is configured.
From an SEO standpoint, the main side effect was the auto-generation of invalid standalone pages, largely interpreted as duplicates by Googlebot.
Discovered, currently not indexed
Precisely, invalid URLs were classed as “Discovered, currently not indexed” or “URL is unknown to Google” in Google Search Console’s page indexing report, despite being submitted to the XML sitemap.
This indicates that either Google never indexed or deprioritized them due to low value.
Dig deeper: Understanding and resolving ‘Discovered – currently not indexed’
Several URLS with the likes of /page-category/:/product-xyz offered little to no unique content and stood out only for a varying number of filter marks hydrated client-side by React Router.

After a deep dive, we were highly confident that the issue concerned the web app’s client-side routing using a placeholder (/:/) to generate filtered view pages without sending any requests to the server.
This approach was harmful for SEO because:
- Search engines had a hard time rendering filtered views.
- Search engines missed server requests for new pages.
Search engines had a hard time rendering filtered views
An aggressive client-side routing caused the initial HTML response to lack the necessary content for search engines during the first indexing wave (before JavaScript execution).
This might have discouraged Googlebot from treating these URLs as valid for indexing.
Without loading filters or product listings, the pages may have appeared duplicate to search engines.
Search engines missed server requests for new pages
Because the app couldn’t resolve filtered views (e.g., /:/) at the server level, dynamically generated pages may have been treated as duplicates of their parent pages.
As a result, Googlebot may have quickly phased out the crawl frequency of such pages.
SEO best practices for React client-side routing
Building a performant and search-engine-optimised React app requires a few general considerations to safeguard crawling and indexing.
Organize your app with a clean folder structure
This includes grouping related route files in one folder and breaking routes into small, reusable components for easier maintenance and debugging.
Set up a robust error-handling system
Routing errors leading to non-existent pages can harm SEO and user trust. Consider implementing:
- A catch-all route for undefined paths using:
- p
ath="*": <Route path="*" element={<NotFound />} />
- p
- A custom 404 page to guide users back to your homepage or relevant content.
- Use
ErrorBoundaryto catch in-app errors and display fallback UI without crashing the app.
Migrate to Next.js
While React offers plenty of advantages, it’s important to remember that it’s fundamentally a library, not a full framework.
This means developers often have to integrate multiple third-party tools to handle tasks such as:
- Routing.
- Data fetching.
- Performance optimization.
Next.js, on the other hand, provides a more complete solution out of the box. Its biggest advantages include:
- Server-side rendering as a default option for faster, SEO-friendly pages.
- Automatic code splitting, so only the necessary JavaScript and CSS are loaded per page.
This reduces heavy JavaScript loads on the browser’s main thread, resulting in faster page loads, smoother user experiences, and better SEO.
In terms of SEO action items, the case study suggested a number of best practices, which we actually handed to web devs to act upon.
Validate and optimize dynamic routes
- Build clean, SEO-friendly URLs:

/category/filter-1/filter-2
/category/:/
- Ensure dynamic segments (e.g.,
/category/:filter) don’t lead to broken or empty views.
Use redirects to manage canonicals and avoid duplicates
- Add fallbacks or redirects for empty filters to prevent Google from indexing duplicate or meaningless URLs.
- Implement 301 redirects from user-generated canonical URLs to the correct canonical version selected by Google.
- For example, set HTTP 301 redirect:
/parent-category/:/→/parent-category/
- For example, set HTTP 301 redirect:
Leverage pre-render to static resources or server-side rendering
Pre-rendering is usually the more affordable option, and it’s likely the one your IT or development team will choose for your web app.
With this method, a static HTML version of your page is generated specifically for search engine crawlers.
This version can then be cached on a CDN, allowing it to load much faster for users.
This approach is beneficial because it maintains a dynamic, interactive experience for users while avoiding the cost and complexity of full server-side rendering.
Bonus tip: Caching that pre-rendered HTML on a CDN helps your site load even faster when users visit.




