
Cloudflare’s Pay Per Crawl: A turning point for SEO and GEO

The content economy is in trouble.
AI crawlers read websites, summarize information, and offer answers without sending users to the original source.
The result?
A dramatic drop in traffic from AI models, declining ad revenue, and a growing threat to the business model that has powered the web for decades.
Now, Cloudflare is stepping in with a new approach.
Just two weeks ago, CEO Matthew Prince said in an interview with Axios:
- “AI is going to fundamentally change the business model of the web. The business model of the web for the last 15 years has been search. One way or another, search drives everything that happens online.
Last week, Cloudflare introduced a possible solution: Pay Per Crawl, a first-of-its-kind monetization layer that lets publishers charge AI bots (like OpenAI’s GPTBot or Anthropic’s ClaudeBot) for accessing their content.
It’s not a complete redesign of how the web works, but rather a new layer built on top of existing web infrastructure.
The system uses the rarely implemented HTTP 402 “Payment Required” response code to block or charge bots that attempt to crawl a site.
So, how does it work, and what does it mean for the future of generative engine optimization (GEO)?
Let’s break it down.
The unspoken deal is breaking – for the first time
It’s worth stepping back for a moment to understand the deeper context behind Cloudflare’s move, as Prince highlighted last week.
Nearly 30 years ago, two Stanford grad students started working on a research project called “Backrub.”
That project became Google. But it also became something bigger: the foundation of the web’s business model.
The unspoken deal between Google and content creators was simple:
- Let us copy your content to show it in search results, and in return, we’ll send you traffic.
- You, as the creator, could monetize that traffic by running ads, selling subscriptions, or just enjoying the satisfaction of being read.
Google built the entire ecosystem that supports that deal:
- Google Search generated the traffic.
- Google bought DoubleClick and launched AdSense to help you earn from it.
- Google acquired Urchin to create Google Analytics so you could measure everything.
It worked.
For decades, this agreement was what kept the open web alive.
But now, that deal is starting to fall apart.
For the first time, Google’s search market share is declining, and what’s replacing them?
AI.
Prince put it plainly:
Ten years ago, Google crawled two pages for every visitor it sent to a publisher.
Six months ago, the ratios were:
- Google: 6:1
- OpenAI: 250:1
- Anthropic: 6,000:1
And today:
- Google: 18:1
- OpenAI: 1,500:1
- Anthropic: 60,000:1
The trend is clear: AI reads, learns, and answers, but rarely sends users back.
The mutual value exchange that once powered the web is quietly collapsing, and content creators are being left out of the equation.
How Cloudflare plans to change the game
When you think about it, the solution is actually pretty smart.
Instead of forcing website owners to choose between two extremes – either block AI crawlers completely or give them full access for free, Cloudflare introduces a third option: charge them.
Here’s how it works.
- Every time an AI crawler requests content, the server can respond with an HTTP 402 Payment Required, including the price for access.
- If the crawler agrees to pay, it sends a follow-up request with a payment header, and the server returns the content with a 200 OK response.
- If it doesn’t, no access is granted.

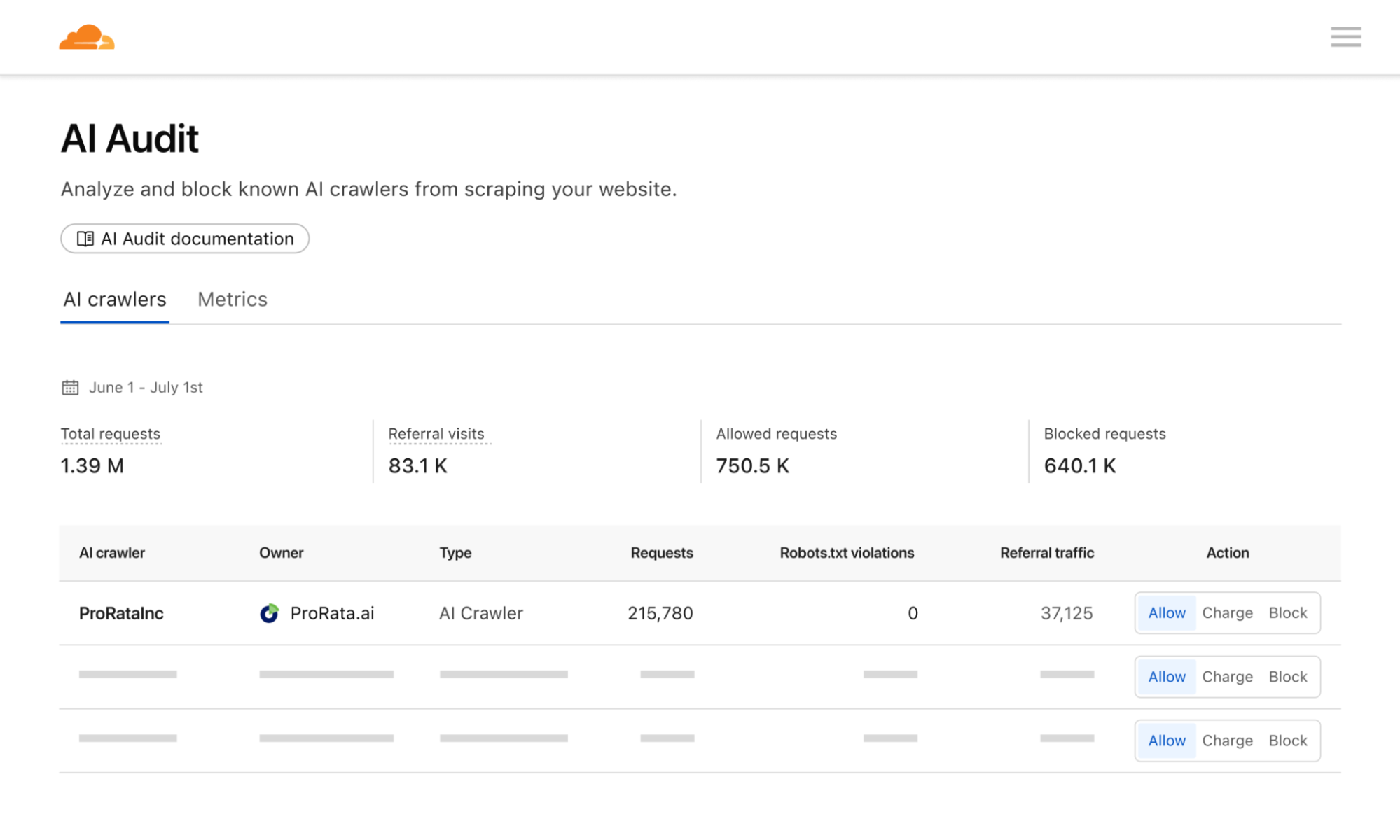
Within the Cloudflare dashboard, site owners will be able to set one of three access rules for each individual AI crawler:
- Allow: Grant full access (HTTP 200).
- Charge: Require payment per request (HTTP 402 with price info).
- Block: Deny access (HTTP 403), but with a hint that payment could be negotiated in the future.
It’s like introducing an API between content and generative models, where information isn’t just free-floating knowledge; it’s now a monetizable digital asset.
And let’s be clear: this isn’t some garage-stage startup trying to shake up the web.
Cloudflare powers the CDN infrastructure for over 20% of all websites, including media companies, content platforms, governments, and major brands, according to company data, .
Sites like Reddit, Medium, Shopify, Udemy, and The Guardian all run through Cloudflare’s network.
That means one simple thing: if Cloudflare decides to limit access, it can do so at a massive scale.
But scale is only part of the picture.
Cloudflare also knows exactly which bots are visiting these sites and how often.
- Bytespider, the AI crawler operated by ByteDance (parent company of TikTok), is the most active, visiting over 40.4% of all Cloudflare-protected domains.
- Next up: GPTBot from OpenAI, at 35.5%, followed by ClaudeBot from Anthropic at 11.2%.
- Interestingly, GPTBot, despite being the most “mainstream,” is also one of the most frequently blocked bots across the network.

Cloudflare notes that many publishers aren’t even aware that AI crawlers are visiting their sites so aggressively. The scale of this hidden scraping is likely far larger than most realize.
How will Pay Per Crawl impact SEO?
First, let’s be clear: Cloudflare will not block BingBot, Googlebot, or any traditional search engine crawlers by default.
However, it does block AI crawlers like GPTBot or ClaudeBot by default, particularly for new websites joining the platform.
Site owners can override this setting and decide which bots to allow, block, or charge using Cloudflare’s new access rules.
The update focuses specifically on AI models, crawlers from companies like OpenAI and Anthropic that gather content to train or power large language models (LLMs), rather than to serve real-time search results.
That said, for the first time, Cloudflare is also giving publishers the option to block or charge traditional search engine crawlers, a level of control that simply didn’t exist before.
Will publishers actually do that?
Probably not, at least not most of them.
Blocking Google or Bing still means risking a huge slice of valuable organic traffic, and for many, that’s too high a price.
And while The Wall Street Journal recently reported a noticeable drop in publisher traffic due to AI-driven search experiences, Google is still responsible for a significant share of most publishers’ traffic today, often 30-60% or more, depending on the site.

But that’s starting to change.
A growing number of major publishers have joined Cloudflare’s Pay Per Crawl initiative, including:
- TIME.
- The Atlantic.
- ADWEEK.
- BuzzFeed.
- Fortune.
- Quora.
- Stack Overflow.
- Webflow.
This publication, which first reported the story, is among them.
So while SEO is still too important for most to walk away from, for the first time, the power to say “no,” or at least “pay up,” is officially on the table.
Dig deeper: 3 reasons not to block GPTBot from crawling your site
How will Pay Per Crawl impact GEO?
Absolutely, and more deeply than you might think.
To understand why, let’s use ChatGPT as an example. As many know, the premium version of ChatGPT performs real-time searches using Bing.
But behind the scenes, there are actually two separate processes at work:
Model training (Training data)
- Before the model can search anything, it first needs to be trained. This is when LLMs learn how language works and build their knowledge of the world, using massive datasets that include text, code, images, and information pulled from across the public web.
- That content is gathered by dedicated AI crawlers like GPTBot (OpenAI), AnthropicBot (Anthropic), and similar bots operated by Google and Meta. You can read more about OpenAI’s data collection process here.
Real-time information retrieval
- After the model is trained, it can pull fresh data from the web via external tools, for example, ChatGPT’s Bing integration.
At first glance, you might think, “If my site isn’t blocking Bing, ChatGPT will still see it when users search, so what’s the big deal?”
But here’s the key distinction:
- Training is what builds the model’s foundational understanding of the world, its sense of language, topics, context, and domain expertise.
- Real-time search is just a way to supplement that understanding, not replace it.
And that’s where Pay Per Crawl starts to matter.
As more websites restrict access to AI crawlers, the training process becomes limited, and that creates three major effects.
Decline in answer quality (even with real-time search)
- Even if the model can “see” your site via Bing or Brave, it won’t know how to interpret or prioritize your content if it wasn’t exposed to similar material during training.
Built-in bias toward known sources
- Models tend to favor sources they’ve seen during training; they “trust” them more.
- If your content wasn’t part of that process, you might be overlooked or less visible in AI-generated answers, simply because the model doesn’t recognize your tone, format, or authority.
Long-term impact on GEO
- As more websites opt into Pay Per Crawl and limit access, the overall training data available to AI models becomes smaller.
- Sites that weren’t visible during training won’t become part of the model’s “mental map,” even if they’re technically accessible during real-time search.
Bottom line
Real-time search may still function, but without a strong foundation, the model won’t know what to look for, how to interpret it, or why your content matters.
GEO isn’t just about visibility; it’s about whether the model knows you, trusts you, and understands you. And all of that starts with training.