The ABCs of Google ranking signals: What top search engineers revealed
The U.S. Department of Justice released several new trial exhibits as part of the ongoing remedies hearing. These exhibits include interviews with two key Google engineers – Pandu Nayak and HJ Kim – which offer insights into Google’s ranking signals and systems, search features, and the future of Google.
Key Google search ranking system terminology
Nayak defined some key Google terminology and explained Google’s search structure:
- Document: What Google calls a webpage, or its stored version.
- Signals: How Google ranks documents that ultimately generate the SERP (search engine results pages). Google talked about using predictive signals from machine learning models as well as “traditional signals,” likely meaning based on user-side data (what Google has previously called user interactions – e.g., clicks, attention on a result, swipes on carousels, entering a new query). Broadly, there are two types of ranking signals:
- Raw signals. These are individual signals. Google has “over 100 raw signals,” according to Nayak.
- Top-level signals. This is a combination of multiple raw signals.
Other signals discussed by the engineers included:
- Q* (“Q star”): How Google measures document quality.
- Navboost: A traditional signal measuring user clicks on a document for a query, segmented by location and device type, using the last 13 months of data.
- RankEmbed: A primary Google signal, trained with Large Language Models (LLMs).
- PageRank: An original Google signal, still a factor in page quality.
Google also uses Twiddlers to re-rank results (which we learned about from last year’s Google’s internal Content API Warehouse leak). An internal “debugging interface” lets engineers see query expansion/decomposition and individual signal scores that determine final search result ranking.
Google discontinues poorly performing or outdated signals.
Navboost: Not a machine learning system
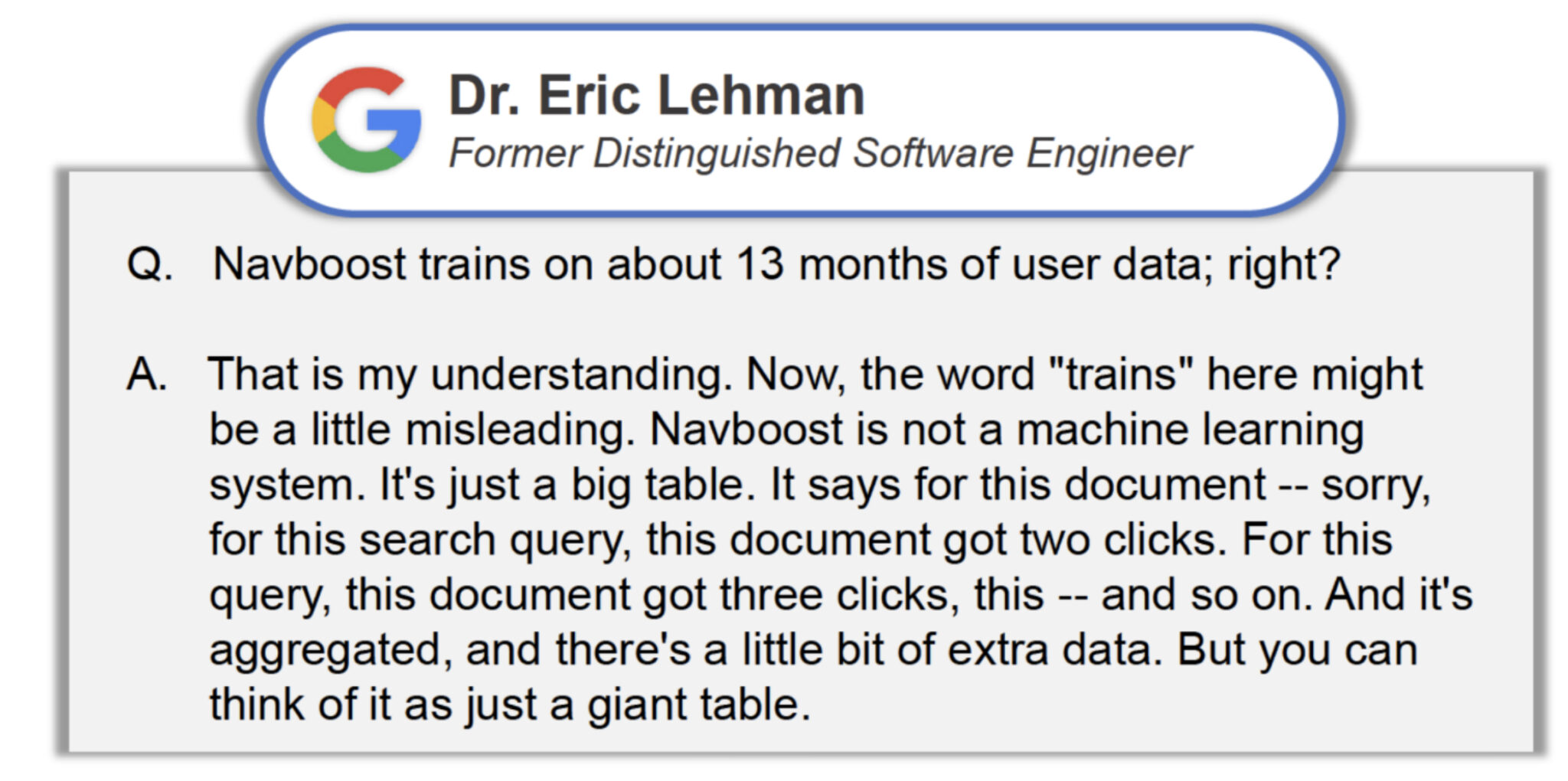
Ex-Googler Eric Lehman was asked whether Navboost trains on 13 months of user data, and testified:
- “That is my understanding. Now, the word ‘trains’ here might be a little misleading. Navboost is not a machine learning system. It’s just a big table. It says for … this search query, this document got two clicks. For this query, this document got three clicks … and so on. And it’s aggregated, and there’s a little bit of extra data. But you can think of it as just a giant table.”

Google Search: From tradition to machine learning
Google’s search evolved from the traditional “Okapi BM25” ranking function to incorporate machine learning, starting with RankBrain (announced in 2016), then, later, DeepRank and RankEmbed.
Google found that BERT-based DeepRank machine learning signals could be “decomposed into signals that resembled the traditional signals” and that combining both types improved results. This essentially created a hybrid approach of traditional information retrieval and machine learning.
Google “avoids simply ‘predicting clicks,’” because they’re easily manipulated and don’t reliably measure user experience.
RankEmbed
A key signal, RankEmbed, is a “dual encoder model” that embeds queries and documents into an “embedding space.” This space considers semantic properties and other signals. Retrieval and ranking are based on a “dot product” or “distance measure in the embedding space.”
RankEmbed is “extremely fast” and excels at common queries, but struggles with less frequent or specific long-tail queries. Google trained it on one month of search data.
Topicality, quality, and other signals
The documents detail how Google determines a document’s relevance to a query, or “topicality.” Key components include the ABC signals:
- Anchors (A): Links from a source page to a target page.
- Body (B): Terms in the document.
- Clicks (C): How long a user stayed on a linked page before returning to the SERP.
These combine into T* (Topicality), which Google uses to judge a document’s relevance to query terms.
Beyond topicality, “Q*” (page quality), or “trustworthiness,” is “incredibly important,” especially in addressing “content farms.” HJ Kim notes, “Nowadays, people still complain about the quality and AI makes it worse.” PageRank feeds into the Quality score.
Other signals include:
- eDeepRank: An LLM system using BERT and transformers to decompose LLM-based signals for greater transparency.
- BR: A “popularity” signal using Chrome data.
Hand-crafted signals
Although machine learning is growing in importance, many Google signals are still “hand-crafted” by engineers. They analyze data, apply functions like sigmoids, and set thresholds to fine-tune signals.
“In the extreme,” this means manually selecting data mid-points. For most signals, Google uses regression analysis on webpage content, user clicks, and human rater labels.
The hand-crafted signals are important for transparency and easy troubleshooting. As Kim explained:
- “The reason why the vast majority of signals are hand-crafted is that if anything breaks Google knows what to fix. Google wants their signals to be fully transparent so they can trouble-shoot them and improve upon them.”
Complex machine learning systems are harder to diagnose and repair, Kim explained.
This means Google can respond to challenges and modify signals, such as adjusting them for “various media/public attention challenges.”
However, engineers note that “finding the correct edges for these adjustments is difficult” and these adjustments “would be easy to reverse engineer and copy from looking at the data.”
Search index and user-side data
Google’s search index is the crawled content: titles and bodies. Separate indexes exist for content like Twitter feeds and Macy’s data. Query-based signals are generally calculated at query time, not stored in the search index, though some may be for convenience.
“User-side data,” to Google search engineers, means user interaction data, not user-generated content like links. Signals affected by user-side data vary in how much they are affected.
Search features
Google’s search features (e.g., knowledge panels) each have their own ranking algorithm. “Tangram” (formerly Tetris) aimed to apply a unified search principle to all these features.
The Knowledge Graph’s use extends beyond SERP panels to enhance traditional search. The documents also cite the “self-help suicide box,” highlighting the critical importance of accurate configuration and the extensive work behind determining the right “curves” and “thresholds.”
Google’s development, the documents emphasize, is driven by user needs. Google identifies and debugs issues, and incorporates new information to improve ranking. Examples include:
- Adjusting signals for link position bias.
- Developing signals to combat content farms.
- Innovating to ensure quality results for sensitive queries like “did the Holocaust occur,” while considering nuanced result diversity.
LLMs and the future of Google Search
Google is “re-thinking their search stack from the ground-up,” with LLMs taking a bigger role. LLMs can enhance “query interpretation” and “summarized presentation of results.”
In a separate exhibit, we got a look at Google’s “combined search infrastructure” (although many parts of it were redacted):

Google is exploring how LLMs can reimagine ranking, retrieval, and SERP display. A key consideration is the computational cost of using LLMs.
While early machine learning models needed much data, Google now uses “less and less,” sometimes only 90 or 60 days’ worth. Google’s rule: use the data that best serves users.
Dig deeper. This is not the first time we’ve gotten an inside look at how Google Search ranking works, thanks to the DOJ trial. See more in these articles:
- 7 must-see Google Search ranking documents in antitrust trial exhibits
- How Google Search and ranking works, according to Google’s Pandu Nayak
The DOJ trial exhibits. U.S. and Plaintiff States v. Google LLC [2020] – Remedies Hearing Exhibits: